- August 11, 2005
- Reason for update: JHashtable->containsKey(...) was updated
Update
For some reason, the containsKey would throw true if it was not contained and false if the key was contained -- the inverse of the expected functionality. This was reported by Hongbin Huang (huang_hongbin@yahoo.com).
- April 9, 2005
- Reason for update:
JHashtable was updated online
Update
For some reason, JHashtable source files were not updated in the zip file for download. As a result, all downloads since March 17, 2005 update continued to have the corrupted JHashtable. I thank Jason Wang from Texas Instruments for bringing this to my attention.
- March 17, 2005
-
Reason for update:
JHashtable was corrupted some how.
Update
The JHashtable library for some reason was not compiling and producing many compile issues -- even variables were being used that were not declared. I am not sure how this occured, however I revised the JHashtable to compile correctly in Visual Studio 2003.
- March 17, 2004
-
Reason for update:
Update all classes for modern C++ compiler compliance
Update
All the classes where revised and tested to compile with the latest compiler. This originated due to the Microsoft C++ compiler in Visual Studio .NET no longer having default support for <iostream.h> and related libraries in favor of the STL recomended.
All the generic collection classes are now separated into .h and .cpp files.
JHashtable was revised with a couple of private functions to promote reuse as well.
All libraries have been tested to compile "as is" in the latest Microsoft C++ compiler as well as Linux.
- July 7, 2003
-
Reason for update:
Update of the JVector class.
Bug
Gary Pickrell (gap@eskimo.com) commented on a bug with the implementation of insertElementAt() method of JVector. Using insertElementAt(0,data) on an empty Vector sets the vector's size() to 2 rather than 1. This is because addElement() increases m_size and then insertElementAt() also does. As a result, Gary suggested moving the incrementation of m_size to inside the else loop:
void
JVector<etype>::insertElementAt( const Etype &obj, int index )
{
if ( index == m_size )
addElement( obj );
else
{
...
m_size++;
}
}
|
- Dec 5, 2002
- Reason for update:
Update of the JString & JHashtable classs.
Redundancies Curtis Krauskopf (from decompile.com) commented on redundancies with the implementation of verifyIndex() method of JString. It has a conditional check (index < 0). Since index is an unsigned int, it is always zero or positive and thus this check is always false. This condition was removed.
JHashtable has a private member called NULL_ITEM. This item is an instantiation of objType (the type used for the values in the hashtable). This template parameter can contain anything for physical objects o pointers of physical objects. As a result, if it is instantiated with a pointer type, it is in essence an unassigned pointer. Likewise, as an object type, the user is not given the opportunity to specify the value of such object for flexibility. As a result, Curtis suggested adding the following method:
void
JHashtable<KeyTypeObjType,>::setNullItem( const ObjType &usrDefValue )
{
NULL_ITEM = usrDefValue;
}
|
- Feb 28, 2002
-
Reason for update:
Update of the JVector class.
Minor Bug Dave O'Keefe (okeefe@cs.stanford.edu) from Standford University commented on a possible bug with the implementaiton of InsertElementAt() vs setElementAt(). After some digging, it turned out that verifiedIndex() was checking against m_capacity instead of m_size to determine if index is valid. This in turn produced unexpected results when one tried to insert an element which exceeded the m_size but yet was lower than m_capacity. The insertElementAt() was also modified to make sure inserting at the end of the vector is handled appropriately.
- June 12, 2001
-
Reason for update:
Update of the JString class.
Minor Bug Subbiah, Venkat (vsubbiah@corvis.com) discovered a minor problem with the destructor ~JString(); . The destructor compares BufferLen with -1. BufferLen is defined as UINT which is a typedef for unsigned int -- thus BufferLen can never be negative. The code was revised to check ( BufferLen > 0 ).
- July 30, 2000
- Reason for update:
Update of the JVector class.
Bug
The insertElementAt( const Etype &obj, UINT index ); performs some efficient shuffling of data.
Adam Doppelt (amd@gurge.com) discovered a minor problem when calling the function on an empty Vector. The algorithm would not set any position within the capacity of the vector with the associated value. The algorithm was revised to ensure proper operation regardless of the state of the Vector.
|
Revised function |
template <class Etype>
void
JVector<Etype>::insertElementAt( const Etype &obj, UINT index )
{
verifyIndex( index );//this will throw if true
if ( m_size == m_capacity )
ensureCapacity( m_capacity + m_increment);
Etype* newItem = new Etype(obj);//pointer to new item
Etype* tmp; //temp to hold item to be moved over.
for( UINT i = index; i <= m_size; i++ )
{
tmp = m_pData[i];
m_pData[i] = newItem;
if ( i != m_size )
newItem = tmp;
else
break;
}
m_size++;
}
|
- July 30, 2000
- Reason for update:
Update of the JVector class.
Bug
The verifyIndex( UINT index ) const; improperly checked the index value against the size of the contents within the vector utilizing m_size rather than checking it against the capacity of the vector utilizing m_capacity.
- July 21, 2000
- Reason for update:
Update of the JHashtable class.
Bug
The JHashtable::rehash() performs some complex but highly efficient shuffling of data. It is usually called when the hashtable exceeds the load factor relative to it's capacity.
Roxana Arama (roxanaa@tlc.ro) discovered a minor memory leak during the final step of the function. As shown in the diagram, once the rehash() function has allocated a newTable of pointers to store all the chains, and moves the chains over. The oldTable, an array of pointers, is no longer necessary since the hashTable's internal table already has been assigned to the the newTable.
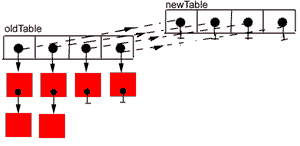
- January 31, 2000
- Reason for update:
Update of the JHashtable class.
Bug
The JHashtable::clear() implementation removes all the elements stores in the hashtable. Jeremy Friesner (jaf@chem.ucsd.edu) from University of California San Diego, noticed the m_count variable was overlooked and not reset to 0.
- August 9, 1999
- Reason for update:
Update of the JString class.
Functionality
The JString::replace( char findChar, char replaceChar ) implementation replaced only the first occurance of a character instead of replacing all occurances. It has been revised to now replace all occurances as the overloaded function for string replacement.
- July 30, 1999
- Reason for update:
Update of the CGIparse class.
Functionality
There was a functionality issue brought up by Philippe Chaintreuil (peep@thefront.com) and Matthew Galati (magal11@us.ibm.com) independently. This functionality issue involves the valueOf() and getNextValue() functions. As originally designed, the getNextValue() function must be called after a valueOf() call. This function was specifically added to provide support for form elements that hold multiple values -- as in the mutiple selection box:
<select name="candy" size="3" multiple>
<option>KitKat
<option>M&M
<option>MarsBar
<option>Twix
<option>Crunch
</select>
|
In the C++ code, one would call valueOf("candy") to get the first value selected, and then subseqent calls to getNextValue() would return any additional values submited with the same variable name.
The storge/retrieval mechanism of the class assumes multiple selected values are transmitted sequentially one after the other via the browser. Although this is typically the case, the class cannot assume this to always be true. As a quick and simple example, the following form would produce separated keys of the name "candy".
<form method="post" action="">
<input type="hidden" name="A" value="KitKat">
<input type="hidden" name="A" value="Snickers">
<input type="hidden" name="A" value="Mars Bar">
<input type="hidden" name="B" value="John">
<input type="hidden" name="A" value="Crunch">
...
</form>
In this scenario, the keys will be stored in the object in the following manner:
 As shown in the image, m_marker will move to the next appropriate key when calling getNextValue() and become NULL as soon as it encounters the "B" key -- thereby never reaching the final "A" key.
As shown in the image, m_marker will move to the next appropriate key when calling getNextValue() and become NULL as soon as it encounters the "B" key -- thereby never reaching the final "A" key.
As a result, the getNextValue() function was modified to not terminate and return NULL if the next key does not match the original key called by the previous valueOf() . Instead it now continues searching the remaining list moving the marker as appropriate.
As an additional benefit, some users may want to quickly jump to the 3rd or 4th value of a particular key. Although this can now be obtained by various calls to getNextValue() as appropriate, the code becomes quite cumbersome. As a result, the valueOf now includes a second optional parameter indicating the occurance sought starting with 0. For example, if one was only interested in the 3rd value of the key "candy" then, calling valueOf("candy",2) would return the appropriate value (Keep in mind, the index starts with 0 as does the index with C++ arrays).
Note:Although the new valueOf() function provides additionaly usability, it should not be abused if efficiency is important. For example, the following code would be many times more inefficient:
...
for( UINT i = 0; i < 10; i++ )
{
const char* name = CGI.valueOf("candy",i);
...
}
...
|
than the more efficient method of:
...
const char* name = CGI.valueOf("candy")
while ( name != NULL )
{
//do some processing here...
name = CGI.getNextValue();
}
...
|
- January 14, 1999
- Reason for update:
Update of the JVector and JString class.
Bug:
There was a minor bug in the JVector class noticed by Carl Pupa (pumacat@erols.com). This minor bug though broght another more serious bug regarding the lastIndexOf() member function of the JVector class into view. Here is the original code before the modification:
JVector<Etype>::lastIndexOf( const Etype &elem ) const
{
for ( UINT i = m_size - 1; i >= 0 ; i-- )
{
if ( *m_pData[i] == elem )
return i;
}
return -1;
}
|
For precise usage and coding, I have recently replaced int types with UINT where ever a negative integer was never needed. In doing this, I neglected to realize the implications of such a change. First of all, this code when compiled with certain compilers generates warnings due to the >= comparison operator in the for condition. The warning is due to a cleaver compiler check notifying the user of the condition ( i >= 0 ) in the for loop will always be true since a UINT is always >= 0.
You can easily see then that any call to this function would create an undefined error once the counter reached 0 and the positive unsigned equivalent of -1 would start as the next iteration. Also, should the function be called on an empty Vector, the incrementor i is automatically initialized to -1 which would produce a similar error.
The solution to both problems is the following function:
JVector<Etype>::lastIndexOf( const Etype &elem ) const
{
//check for empty vector
if ( m_size == 0 )
return -1;
UINT i = m_size;
do
{
i -= 1;
if ( *m_pData[i] == elem )
return i;
}
while ( i != 0 );
return -1;
}
|
The latest version may be obtained at: http://www.mike95.com/c_plusplus/classes/JVector/
- November 7, 1998
- Reason for update:
Update of the JHashtable class.
Bug:
The user must now provide a hash function as mentioned in the header file. Originally, the class contained a default hash function which simply calculated a hash number by summing the bytes of the object and then modulo the total by the hash table size. But this approach could produce erroneous results since one cannot assume, even if the objects are theoretically equal, that their internal structure are the same.
As an example, lets assume we were using a class that represents a drawing as a key of the hashtable. And the drawing class, in order to recreate the drawing when requested, stores a list of brush strokes applied in a particular order internally. Now, let the first drawing be a single stroke and let the second drawing contain the same single stroke as the first drawing plus an additional stroke. Now, a third stroke (an erasing stroke), erases the second stroke applied to the second drawing.
Now physically the drawings are the same since visually there is no difference. Internally though, the second drawing contains 3 strokes while the first drawing contains 1 stroke in its internal list of strokes.
As a consequence, the original default hash function would, in many cases, compute the incorrect hash value for two seemingly identical objects.
The latest version may be obtained at: http://www.mike95.com/c_plusplus/classes/JHashtable/
- September 9, 1998
- Reason for update:
Update of the CGIparse class and minor bug fixes in JVector, JHashtable, and JStack classes.
Library Update - CGIparse:
A user emailed me regarding the printMime() member function of the CGIparse and asking why it was specifically used for "text/html" instead simply any particular mime-type such as image/gif or text/plain. As a result, the member function was updated (while remaining completely backward compatible with previous version's functionality). Originally the function simply printed the Content-type: text/html and set the mime_sent variable to true.
The function now receives two parameters as follows:
printMime( const char* mime, bool isLast )
|
mime defaults to "text/html" and isLast defaults to false. This way if the user calls the function with a specific mime-type as in printMime("specific/mime"), the mime is sent to the browser but the mime is not completed since isLast is false by default -- this is useful if multiple mime-types need to be sent to the browser.
For backward compatibility, printMime now checks for the "text/html" mime type and sets the boolean (mime_sent) variable to true if it finds it…so then if the function is called in it's previous form with no parameters printMime() it's functionality is still the same.
Bug#1:
In JVector class, the removeElement() member function needed to de-reference the m_pData pointer prior to comparing it using the == operator.
Snippet of old code for JVector member function:
...
if ( m_pData[i] == obj )
{
removeElementAt( i );
return true;
}
...
|
Snippet of corrected new code for JVector member function:
...
if ( *m_pData[i] == obj )
{
removeElementAt( i );
return true;
}
...
|
Bug #2:
In JHashtable, the HashItem() function of the class needs to be declared as a constant member function of the class not only because it doesn’t modify any class members, but also because the containsKey() function is declared as a const member function and it makes a call to HashItem. A good compiler will detect the security breech "of a const member function calling a non-const member function" and appropriately report the error.
Bug #3:
In JStack's search() function, the syntax for the for loop is incorrectly coded as:
for( int count = 1, node* pJStack = m_pTOS; pJStack != NULL; count++ )
|
and as such, some compilers take the word "node" is a second int automatic variable declaration. The function was re-written in a more clear and user-friendly way that avoids any compiler issues.
- August 31, 1998
- Reason for update:
Compilation issues with regards to the template based classes.
Problem:
Some compilers do not support the separating of class definitions and class implementation into two separate files (the .h and the .cpp files) when the class is a generic "template" class. A common workaround for this is to include the .cpp file of the class where ever one would normally include the .h file of a specific template class. The problem occurs when one uses the template class in more than one location in the project and thus has included the .cpp file in more than one location to be compiled. Upon compilation, the compiler complains of multiple definitions.
Solution:
For template based classes, the implementation code is now placed in the .h file below the definition and the macro "#pragma once" is used to notify the compiler that the file should be included for compilation once regardless of the number of times it is actually included in the project.
Affected libraries:
JVector, JStack, JHashtable